The same prompt, temperature=0, and fixed seed can still yield different text depending on whether the server runs the request alone or batches it with others. That looks like a bug to many operators. This post explains why the behavior can be correct, and what the vLLM maintainers and issue authors found when they investigated. The argument rests on specific issues, attributed thread excerpts, and measurements you can read for yourself.
The two issues (and why they’re instructive)
Two well-known vLLM issues are directly on point:
- vLLM #5898: Inconsistent Responses with VLLM When Batch Size > 1 even temperature = 0
- vLLM #9567: Models produce different output with different batch sizes
Both are labeled bug, but the resolution of each is what matters.
What #5898 actually shows
- Setup: Llama3-8B, temperature=0, max_tokens=1024, seed=1, OpenAI-compatible server.
- Observation: With batch size 1, the same prompt gives the same response every time. With batch size > 1, the same prompt sometimes gets different responses, often by only one or two words.
- FP16 vs FP32: The author reported the effect with FP16. On #5898, commenter UbeCc tried FP32 on MATH500 and still saw about 10 of 500 pieces differ in dual testing, so FP32 reduces but does not eliminate the variance.
- Root cause (from the thread):
- One contributor (StanHatko) provided a sampler-side fix for the zero-temperature path (avoiding division-by-zero and using an explicit argmax for T=0). That improved consistency; in that comment he attributed remaining variance to CUDA nondeterminism.
- LinJianping then noted: “the inconsistency does not stem from the sampling strategy, as the logits output by the model is unequal. When the model’s data type is set to FP32, the batch result closely aligns with the singleton request.” So there are two layers: (1) a real sampler bug for zero temperature (fixed in PR #12802), and (2) upstream differences in model logits when batch size changes: the forward pass is not batch-invariant in floating-point.
So #5898 shows both a fixable bug (sampler) and expected behavior (different logits from the model under different batching).
What #9567 actually shows
- Setup: Repro script using the same prompt set with batched run vs
max_num_seqs=1, temperature=0, on A100 (and later H100). Model: initially a quantized Llama variant, then alsometa-llama/Meta-Llama-3-8B-Instruct. - Observation: Batched and serial runs produce different outputs; logprobs diverge early in the sequence. Same behavior with
--enforce-eager(so not cudagraph-specific). A Neural Magic dev (tlrmchlsmth) commented: “changes in the problem size can result in different block sizes used for the GEMM, which can affect the order of the accumulation. Losing accuracy with larger batch sizes is definitely not expected behavior.” In the thread, that reads as treating different block sizes and thus different accumulation order as the mechanism, rather than a conventional software bug. - Critical experiment: joerunde (issue author, vLLM collaborator) reported: “when using dtype=float32 with
meta-llama/Meta-Llama-3-8B-Instructthere are no differences in the outputs, so this could just be a numeric precision problem after all.” - Closure: joerunde closed the issue with: “Any objections to closing as working as expected?” tlrmchlsmth agreed. So the maintainers explicitly classified this as expected given precision and reduction order, not a bug to fix in the GEMM/scheduler.
So #9567 is a clear case where different output for different batch sizes was confirmed as numeric precision / reduction order and closed as working as intended.
Output can change even with no hyperparameter change
No hyperparameter change here means the same prompt, temperature, seed, and batch size. Output can still differ between runs if next-token logits differ because the implementation uses a different reduction order (for example nondeterministic or order-sensitive floating-point reductions). That only flips the chosen token when the model is uncertain: when the top two logits are very close (a near-tie). That situation is more likely with a large vocabulary and a model that is not sharply peaked on the next token.
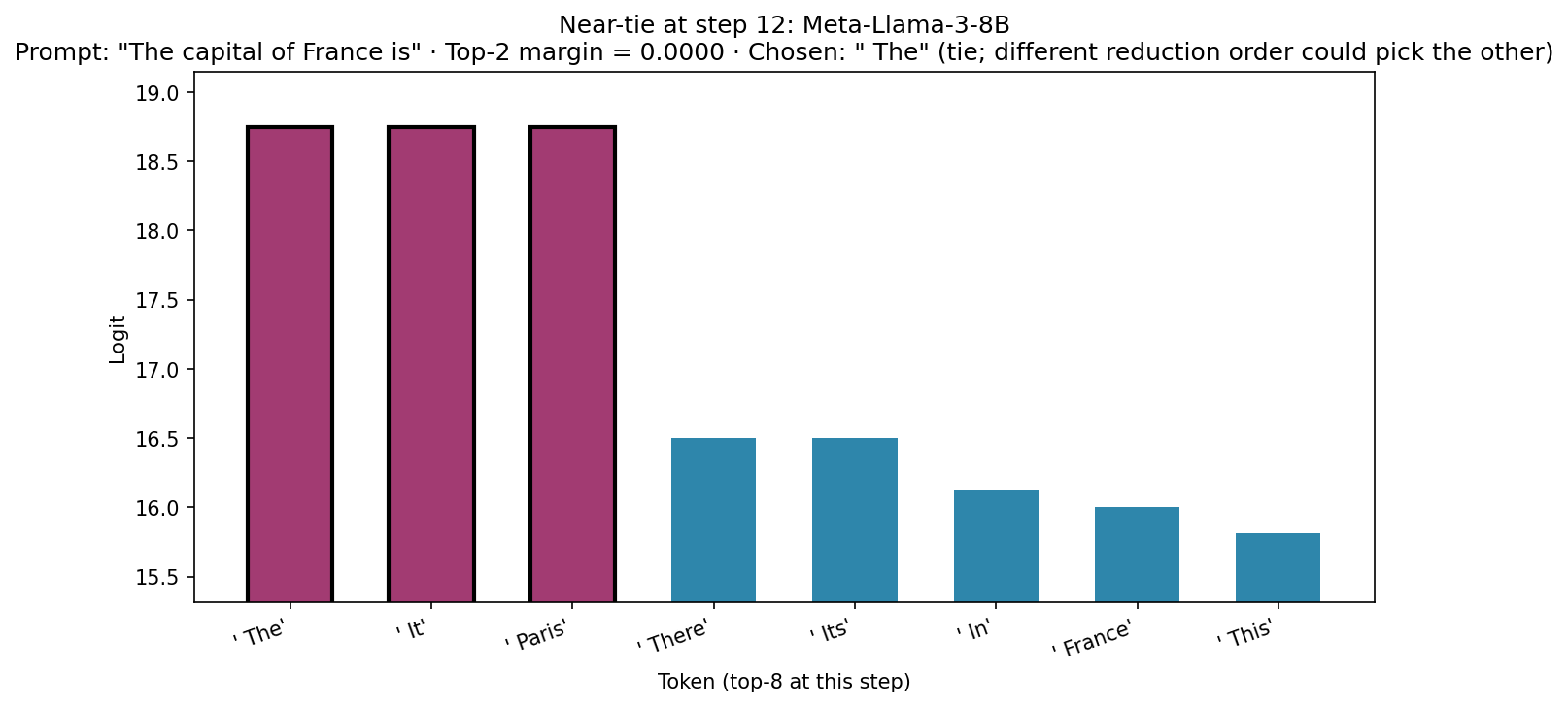
The figure below shows a step where the model is uncertain: on Meta-Llama-3-8B with prompt The capital of France is, at step 12 the top three continuations (The, It, and Paris) share the same logit (three-way tie; top-2 margin 0). With the same hyperparameters, a different reduction order in a later run could break that tie and change argmax, so the output can change even when you don’t change any hyperparameters. In practice, repeated forwards with the same seed often stay deterministic on GEMM-heavy paths, but the mechanism (near-tie plus reduction order) is the same one that causes batch-size flips.
GEMM, run-to-run determinism, and which CUDA ops actually vary
Changing batch size is not the same as running the same configuration twice: when batch size (or sequence length) changes, the library can pick different GEMM kernels and tile sizes, so the order of accumulation changes. That is a deterministic difference between two problem shapes, not necessarily random noise on every launch. That matches what #9567 discusses (different block sizes → different accumulation order).
Run-to-run, plain GEMM is usually deterministic for a fixed input and fixed shape: the same kernel tends to use the same reduction tree, so you often get bit-identical results across repeats. That is the usual experience in HPC and in PyTorch for torch.mm / addmm at fixed sizes. It is not a universal guarantee across every backend, precision mode, or autotuning path, but it explains why reports of CUDA nondeterminism do not imply that every matrix multiply varies from run to run.
Some CUDA ops are known to be nondeterministic across repeats (often atomics or parallel prefix algorithms). For example, testing on an RTX 3090 (PyTorch 2.10+cu128, default settings) shows that torch.mm, addmm, large sum reductions, and bfloat16 GEMM are identical across many repeats; however, scatter_add, index_add, and cumsum produce different outputs starting at repeat 1. So the GPU stack is not globally deterministic; only the ops that dominate a typical transformer forward (GEMM-style work) behaved deterministically in that test.
The takeaway: batch non-invariance is still explained by different numerics when the implementation changes (here: batch size leads to different kernels / accumulation). Run-to-run flips with identical hyperparameters are possible where the graph includes nondeterministic ops or changing heuristics, but are less common because typical transformer forward passes are dominated by deterministic GEMMs.
Why this is correct behavior
- Math is batch-independent. For a single sequence, the transformer’s attention and FFN operations do not mix data across batch indices. So in exact arithmetic, changing other batch rows cannot change the output for your row: batch indices do not mix in the idealized model.
-
Implementations are not exact. Real stacks use different GEMM kernels (and block sizes) for different batch/problem sizes, so batch size 1 vs 2 can change accumulation order even when each run is deterministic on its own. Some CUDA primitives (for example certain indexed reductions, prefix sums) can be nondeterministic across repeats on the same shape; that is separate from batch-size effects. Together, the order of floating-point operations can differ when you change batching, and can sometimes differ between repeats if the graph hits nondeterministic ops. That yields different rounding, hence different logits, hence different argmax when two logits are very close.
-
When top-two logits are close, argmax is unstable. If the model assigns nearly the same score to two tokens, a tiny change in the leading logit (e.g. from a different reduction order) can flip the chosen token. In a well-trained model, that usually means the model was nearly indifferent between two plausible continuations, not that a clearly better answer was replaced by a worse one.
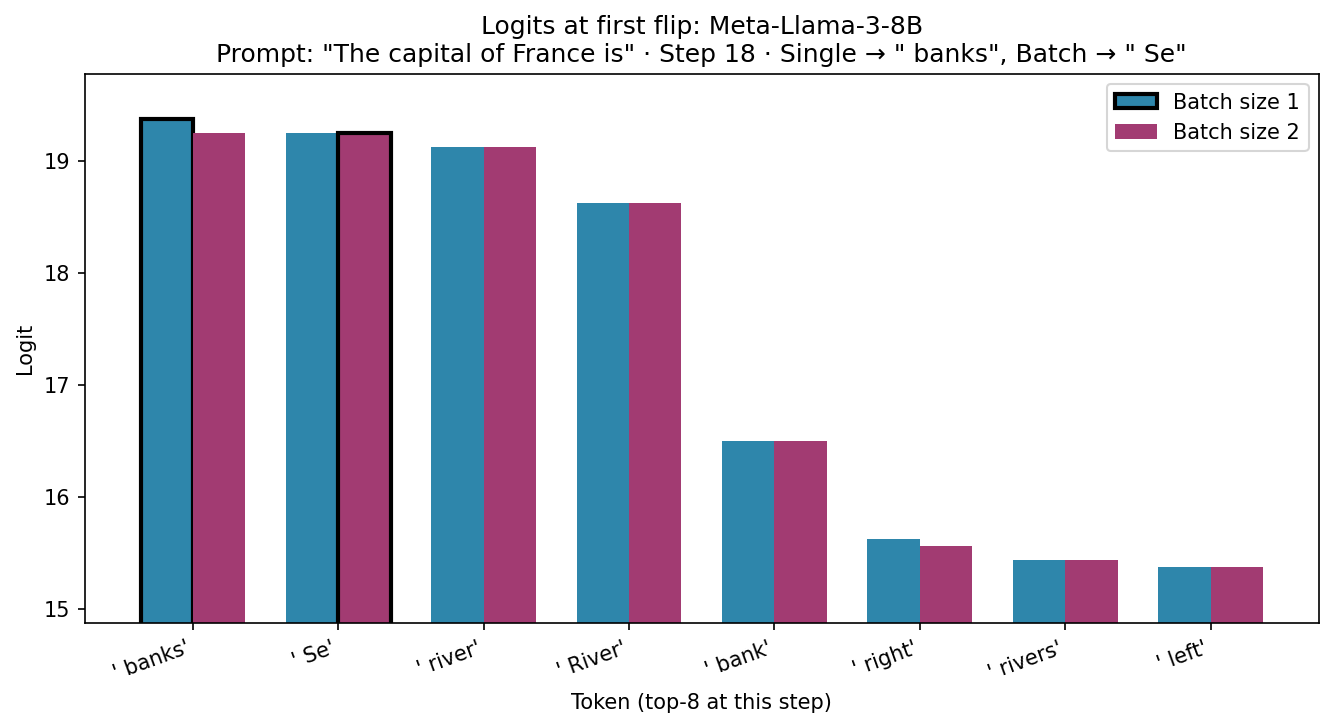
Reproduction: logits when the top token flips. I reproduced the effect with Meta-Llama-3-8B (same prompt, temperature=0, batch size 1 vs 2) and recorded the logits at the first step where the chosen token differed. Below: at that step, the top-8 token logits for the single-sequence run vs the batch-of-two run (first sequence). The black outline shows which token was chosen (argmax): batch size 1 chose banks, batch size 2 chose Se. The top two logits are within 0.125 of each other; the batch forward produced slightly different values (e.g. banks 19.375 → 19.25, Se 19.25 → 19.25), so the tie or near-tie flipped the argmax.
- Real measurements back this.
- #9567: float32 removed the output differences; maintainers closed the issue as working as expected.
- #5898: LinJianping reported that with FP32 the batch result closely aligned with the singleton request; remaining variance was attributed to CUDA nondeterminism.
- Independent reproduction: a brute-force search found an example where the top two logits were very close; Nsight Systems showed different CUTLASS GEMM kernels (e.g.
cutlass_80_wmma_tensorop_f16_s161616gemm_f16_32x32_128x2_tn_align8vs32x32_64x2) and different launch counts (e.g. 3× morecublasLt::splitKreduce_kernelwith batch size 2). So different kernels and reduction patterns do run when you change batch size, which is enough to change floating-point results when logits are close.
So batch non-invariance of sequence model outputs is correct in the sense that it arises from valid implementation choices (different kernels, reduction order) and finite precision, not from cross-batch data leakage or a logical error. The GitHub issues, when read to resolution, support that.
What would be a bug
- Data leakage: Another user’s tokens or logits affecting your sequence. The design (batch dimension as independent lanes) and the issues above do not show that; they show same-prompt-different-output from the same model, same batch row, different numerics.
- Sampler bugs: #5898’s zero-temperature path was a real bug (wrong handling of T=0); that’s fixed in PR #12802. Distinguish a sampler bug from differences in model logits under different batching.
If you need strict reproducibility
To get batch-invariant (and deterministic) inference you have to constrain the implementation: same kernels and deterministic reduction order for every batch size. That has a cost. For example, Thinking Machines report roughly 62% of conventional throughput with their deterministic, batch-invariant setup. Correct behavior here does not come for free: you trade throughput for invariance.
References:
- thinking-machines-lab/batch_invariant_ops
- arXiv:2506.09501 (Understanding and Mitigating Numerical Sources of Nondeterminism in LLM Inference)
- vLLM issues #5898 and #9567 (read the full threads and closure comments)
Summary: Same prompt, temperature=0, different batch size → different text is often correct: math is batch-independent, but implementations can use different GEMM kernels and accumulation order for different batch sizes, so FP results (and thus argmax) can differ when top logits are close. That is largely a deterministic shape-to-shape effect, not random variation in every matrix multiply. Run-to-run nondeterminism is op-dependent: some CUDA ops vary from launch to launch; plain GEMM at fixed shape often does not. The two vLLM issues, read to closure, support the batch-size picture; #9567 was explicitly closed as working as expected.

Leave a comment